Software Engineer
Thomas Simko
Full-stack Developer
About Me
Fast-paced, data-driven development
I make decisions as a programmer based on data. By analyzing and interpreting data, I can reduce development time and boost user satisfaction.
Collaborate and embrace feedback
As a member of a scrum team, I practice open communication, empathy, and a positive attitude. I also value feedback from my teammates.
Leave it better than you found it
Inside and outside the workplace, it's important to clean up after yourself and others. As a software engineer, this means composing clear, concise, and maintainable code.
Skills
Technologies
As a full-stack engineer, I get to work with a variety of technologies. I love learning new languages and frameworks, such as the ones listed below.
React
AngularJS
Java
Python

Firebase

MySQL
Projects
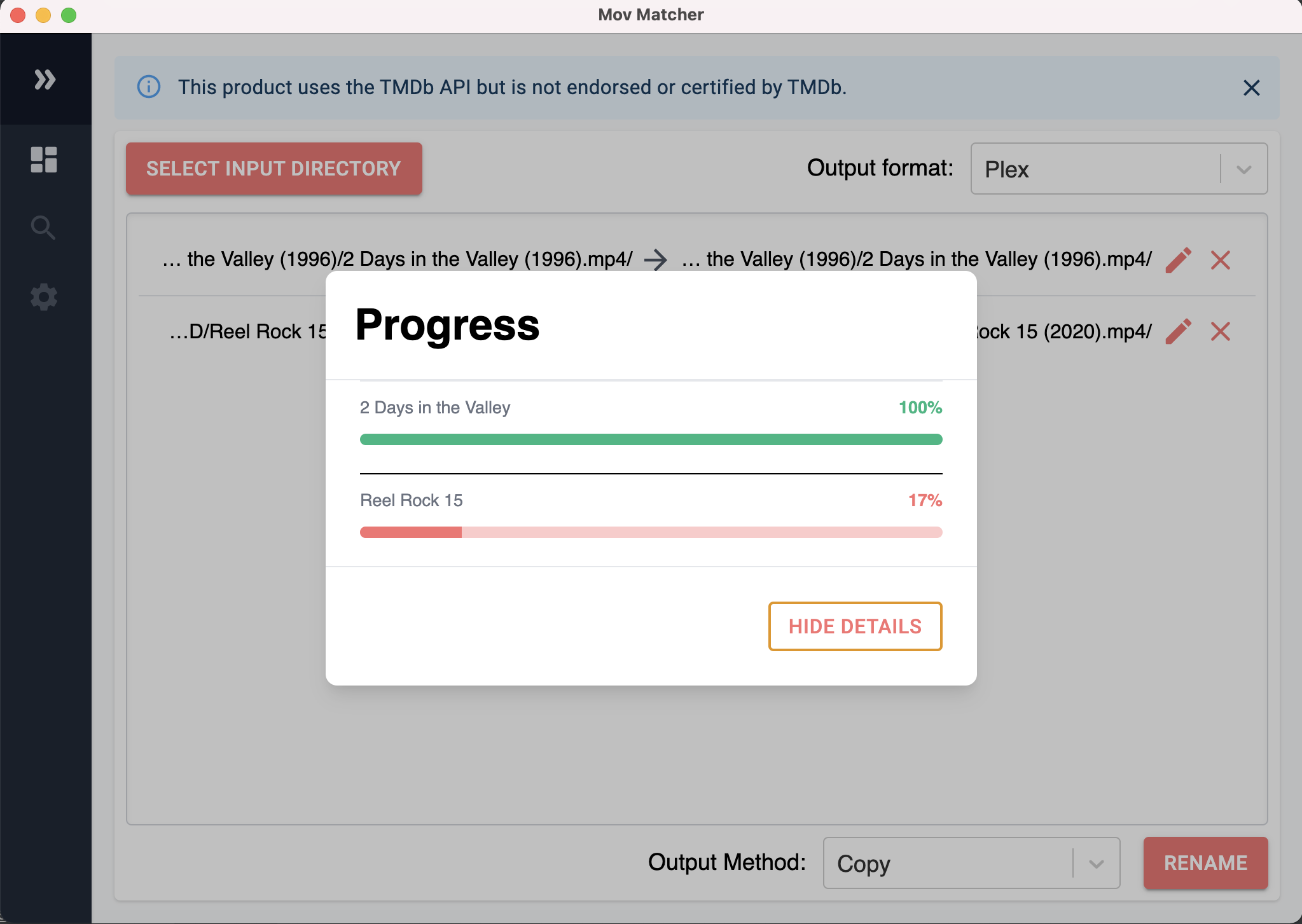
Movie Renamer
ReactElectronElasticSearchTailwindTypescript
As a side project, I'm developing an application that renames movie files to user defined formats. The program watches a directory and if the name-matching algorithm meets a confidence threshold, it renames the files. The algorithm uses fuzzy matching in ElasticSearch with data seeded from The Movie Database API that is indexed using a Python script.

Sensor App
ReactIonicFirestoreTypescript
I developed a cross-platform mobile app using Ionic that subscribes to real-time updates from a variety of Arduino-powered sensors. The sensors post their data to Google Firestore, and the app automatically updates with new data. If a certain threshold is met, the app users can be notified.
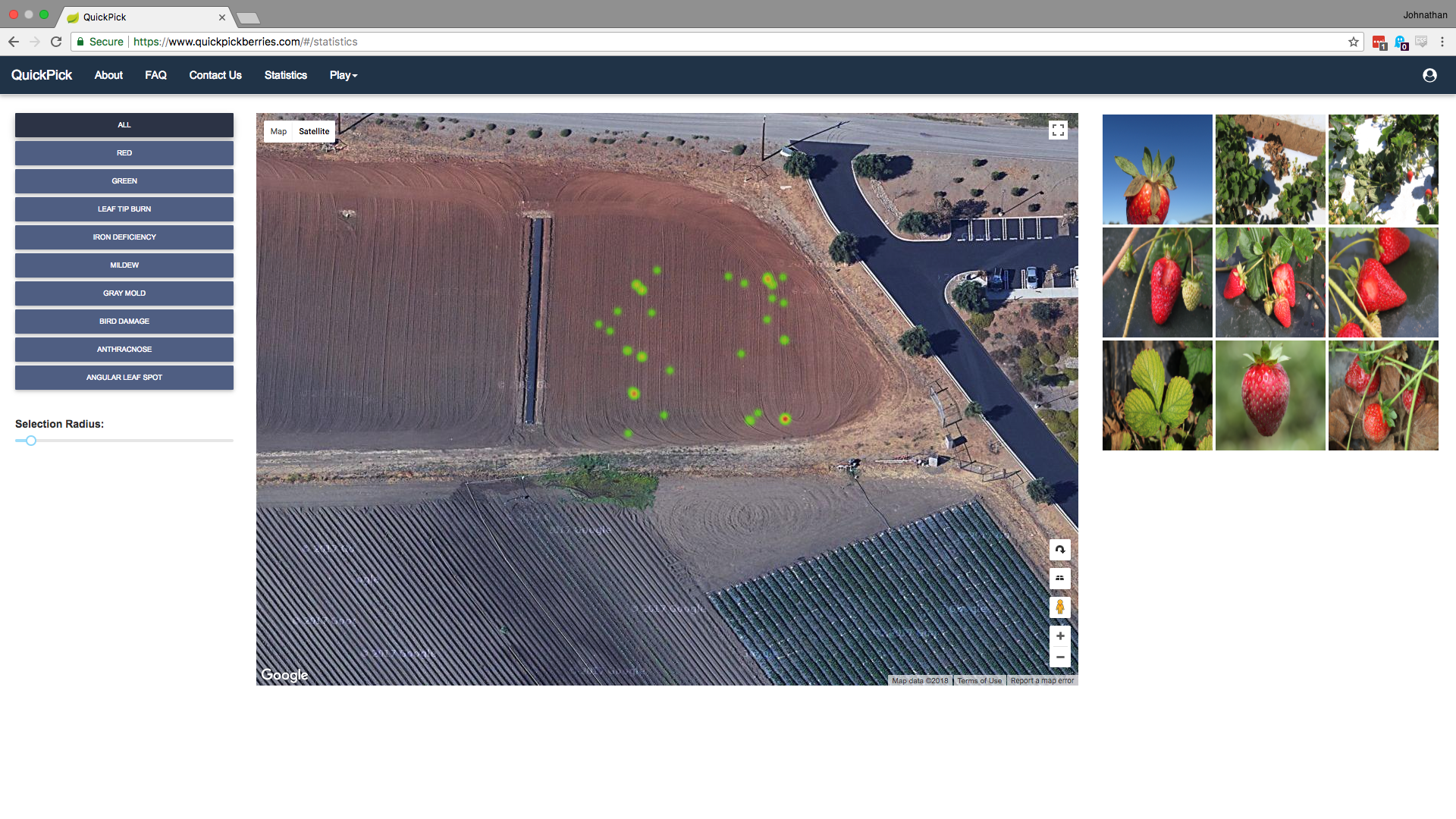
Tele-operated Strawberry Harvester
ReactAWSJava SpringTypescript
In collaboration with the California Strawberry Commission, I served as the front-end technical lead to develop a platform to improve strawberry production through remote operation of strawberry harvesters and analysis of the farm’s data. This project allowed users to control a robot to pick strawberries or classify strawberries as potentially diseased, providing the farm owner a heat map of infestations. The MQTT protocol was used to stream commands to a RaspberryPi-powered robot, which streamed a live video feed back to the browser.
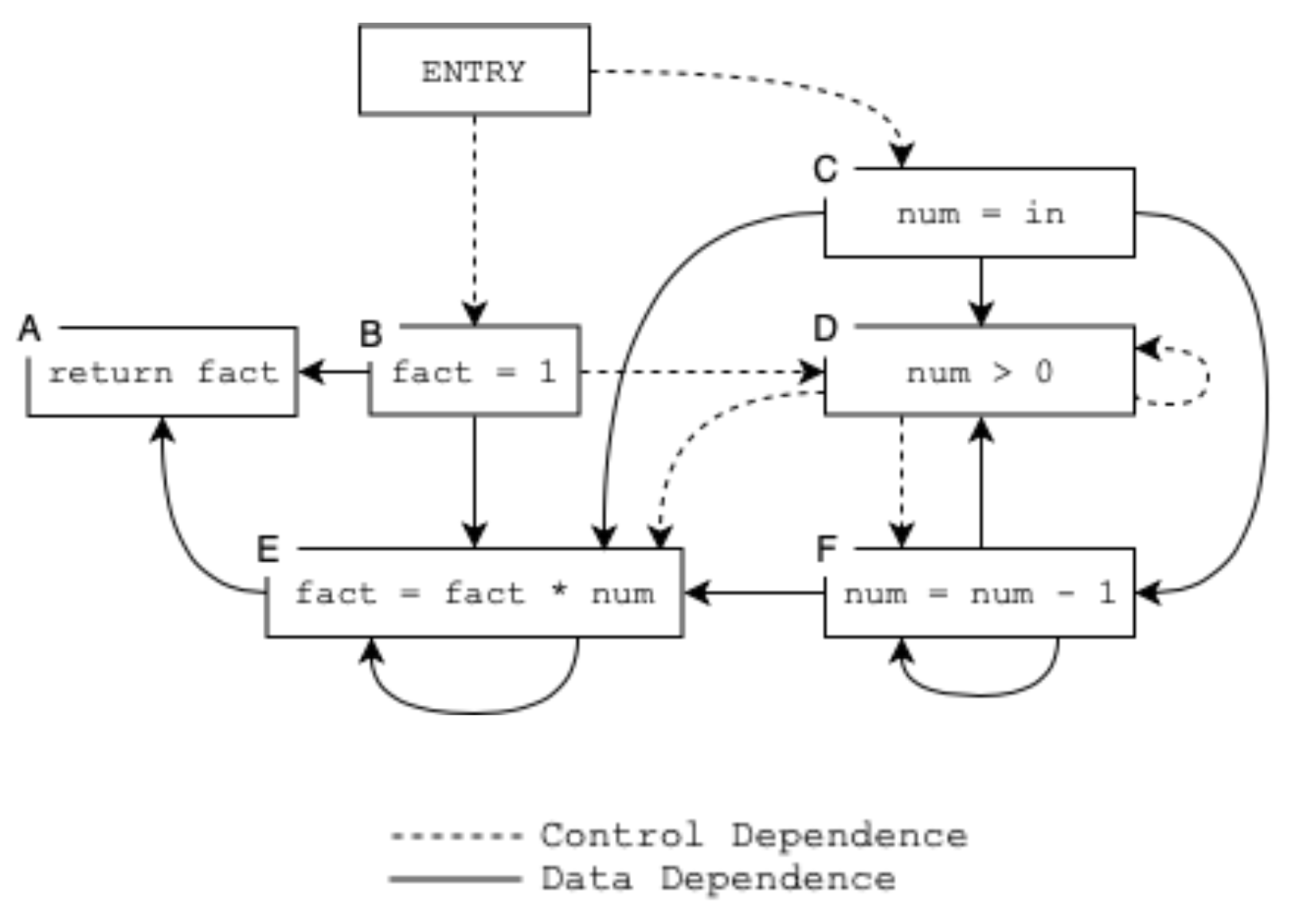
Cloneless: Code Clone Detection via Program Dependence Graphs with Relaxed Constraints
JavaCLI
Code clones are pieces of code that have the same functionality. While some clones may structurally match one another, others may look drastically different. The inclusion of code clones clutters a code base, leading to increased costs through maintenance. While manual clone identification may be more accurate than automated detection, it is infeasible due to the extensive size of many code bases. This thesis outlines a method of detecting clones using a program dependence graph and subgraph isomorphism to identify similar subgraphs, ultimately illuminating clones.